每日經濟新聞 2025-04-08 18:34:42
當地時間4月5日,Meta宣布推出新一代開源大模型Llama 4,稱其在基準測試中領先同行,但開發者實測發現其效果不佳,甚至問題百出,質疑其作弊“刷榜”。Meta深陷輿論漩渦。對此,Meta緊急辟謠,稱相關說法毫無事實依據。
每經記者 宋欣悅 每經編輯 蘭素英
當地時間4月5日,美國科技巨頭Meta宣布推出其新一代開源大模型Llama 4。Llama 4目前有兩個混合專家(MoE)架構的版本,分別為Scout和Maverick。更為強大的Llama 4 Behemoth仍在訓練中。
Meta官方稱,Llama 4在一系列廣泛接受的基準測試中均實現了領先同行的水平,尤其是Llama 4 Behemoth,在多個基準測試中的表現要優于GPT-4.5、Claude Sonnet 3.7和Gemini 2.0 Pro等一眾行業頂尖封閉模型。
然而,就在模型發布后不久,鋪天蓋地的質疑聲涌來。開發者實測Llama 4后發現,其真實效果并不如宣傳中那么驚艷,甚至問題百出。
與此同時,有開發者質疑Meta作弊“刷榜”,根據相關評測基準對模型進行“量身定制”訓練。
知名科技媒體TechCrunch也發文,直指Meta新AI模型的性能測試“具有一定誤導性”。
Meta深陷輿論漩渦之中。對于外界的質疑,當地時間4月7日,Meta生成式AI副總裁艾哈邁德·阿爾·達赫勒(Ahmad Al-Dahle)在社交平臺X上公開回應,明確指出相關說法毫無事實依據。

圖片來源:Meta官網
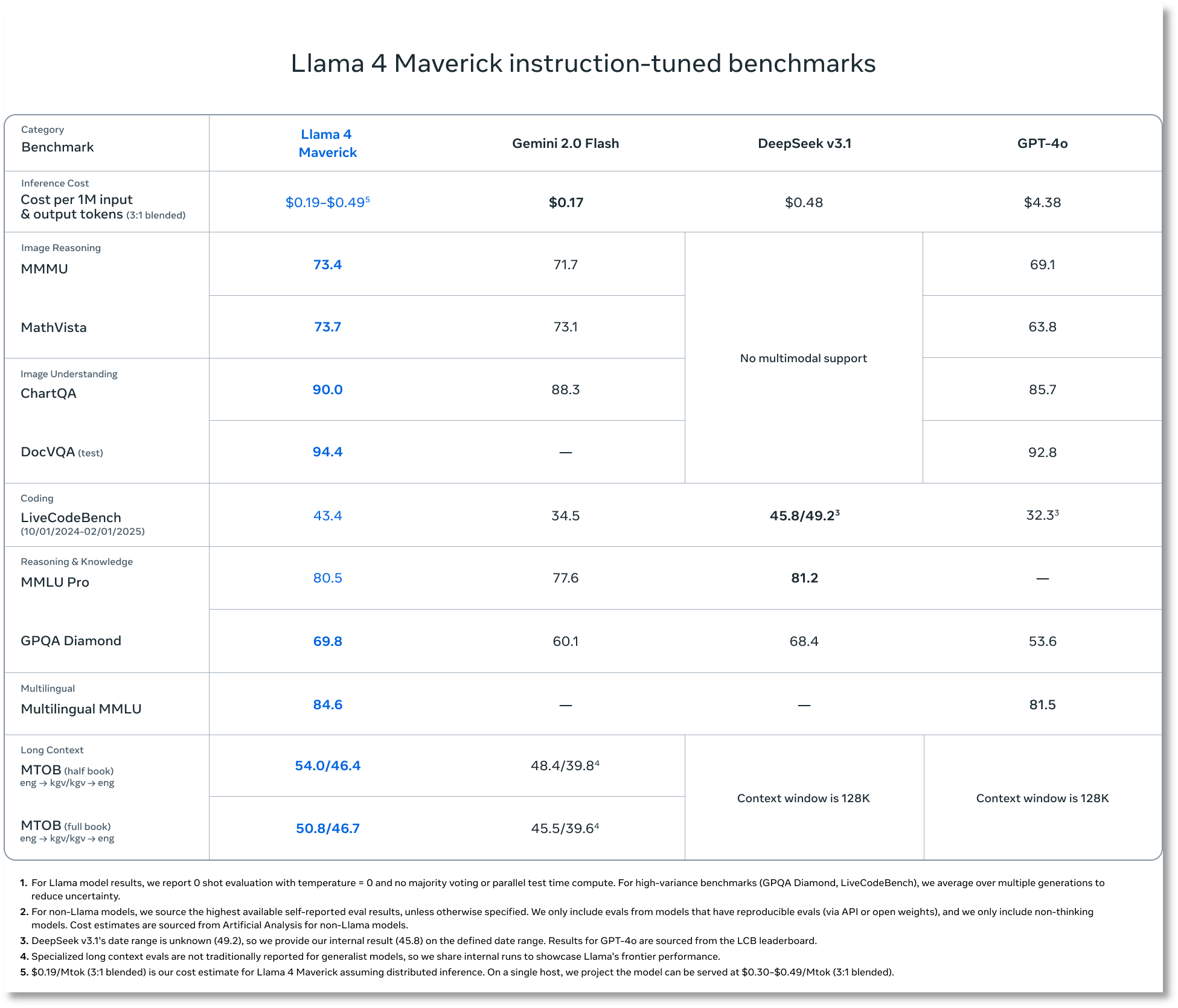
據Meta介紹,Llama 4模型家族使用了混合專家(MoE)架構,原生支持多模態,實力超強,堪稱“全能選手”。
其中,Llama 4 Scout擁有170億活躍參數以及16個專家模塊,提供長達1000萬tokens上下文窗口。在多項基準測試中,Scout的表現優于Gemma 3和Gemini 2.0 Flash-Lite等模型。
Llama 4 Maverick同樣擁有170億活躍參數,專家模塊數量提升至128個。在多項主流基準測試中,其成績超越了GPT-4o和Gemini 2.0 Flash。Meta還特意點名DeepSeek,強調在推理和編碼方面,Llama 4 Maverick可以比肩DeepSeek新開源的V3模型,而其活躍參數還不到DeepSeek新版V3的一半。
被Meta稱為“世界上最聰明的模型之一”的Llama 4 Behemoth則擁有2880億活躍參數和16個專家模塊。在多項主流基準測試中,其性能表優于GPT-4.5、Claude Sonnet 3.7和Gemini 2.0 Pro等行業頂尖模型。
圖片來源:Meta官網
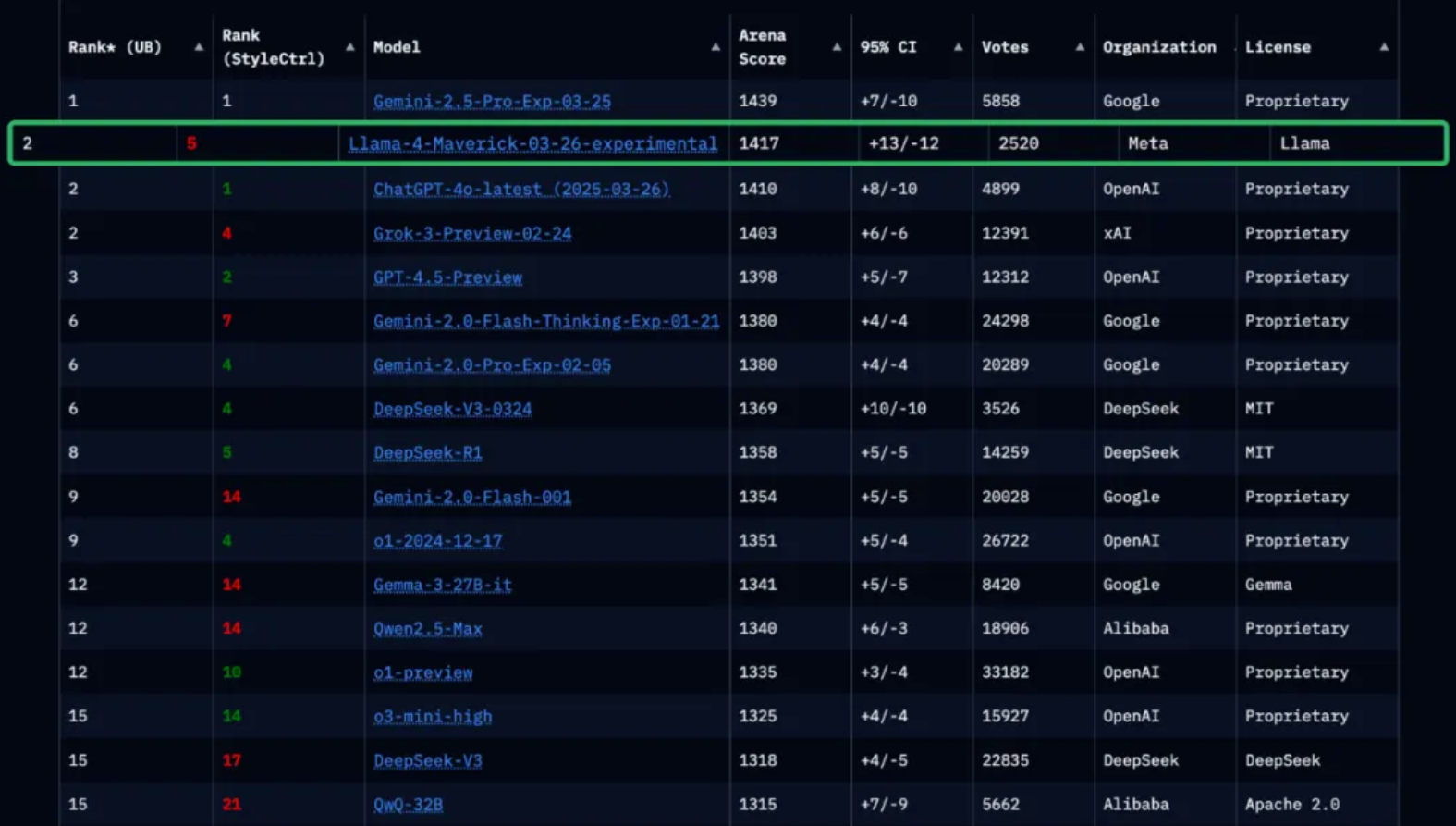
而在大模型競技場上,Llama 4 Maverick表現奪目,總排名位居第二,成為第四個突破1400分的大模型。在開源模型中,Llama 4 Maverick排名第一,超越了DeepSeek。
在困難提示詞、編程、數學、創意寫作等任務的比拼中,Llama 4 Maverick均斬獲第一名。相較于自家前代產品Llama 3(405B)獲得的1268分,Llama 4 Maverick的得分實現大幅躍升,達到了1417分。
圖片來源:大模型競技場
這本應是開源社區的又一狂歡。但開發者們實測發現,Llama 4的效果并不像官方宣稱的那樣驚艷,甚至可以說是問題百出。
Menlo Ventures風險投資人迪迪·達斯(Deedy Das)直言,“Llama 4實際上是一個糟糕的編程模型。”
達斯指出,在專注于編程任務(如代碼生成和代碼補全)的KCORES基準測試中,Llama 4 Scout和Llama 4 Maverick表現欠佳,落后于GPT-4o、Grok 3、DeepSeek-V3等模型。

圖片來源:KCORES LLM Arena
這與此前Llama 4在大模型競技場的表現形成鮮明反差。
有網友直接曝出,Llama 4在大模型競技場上存在過擬合現象,有極大的作弊“刷榜”嫌疑。
在一些實測中,Llama 4在上下文任務的實際表現遠低于預期。Llama 4 Maverick在aider多語言編碼基準測試中的實測得分僅為16%。
Abacus.AI首席執行官賓杜?雷迪(Bindu Reddy)評論道:“人類的評估已經毫無意義了……根據現實世界的表現,Llama 4 Maverick應該遠遠排不上第一或第二。”
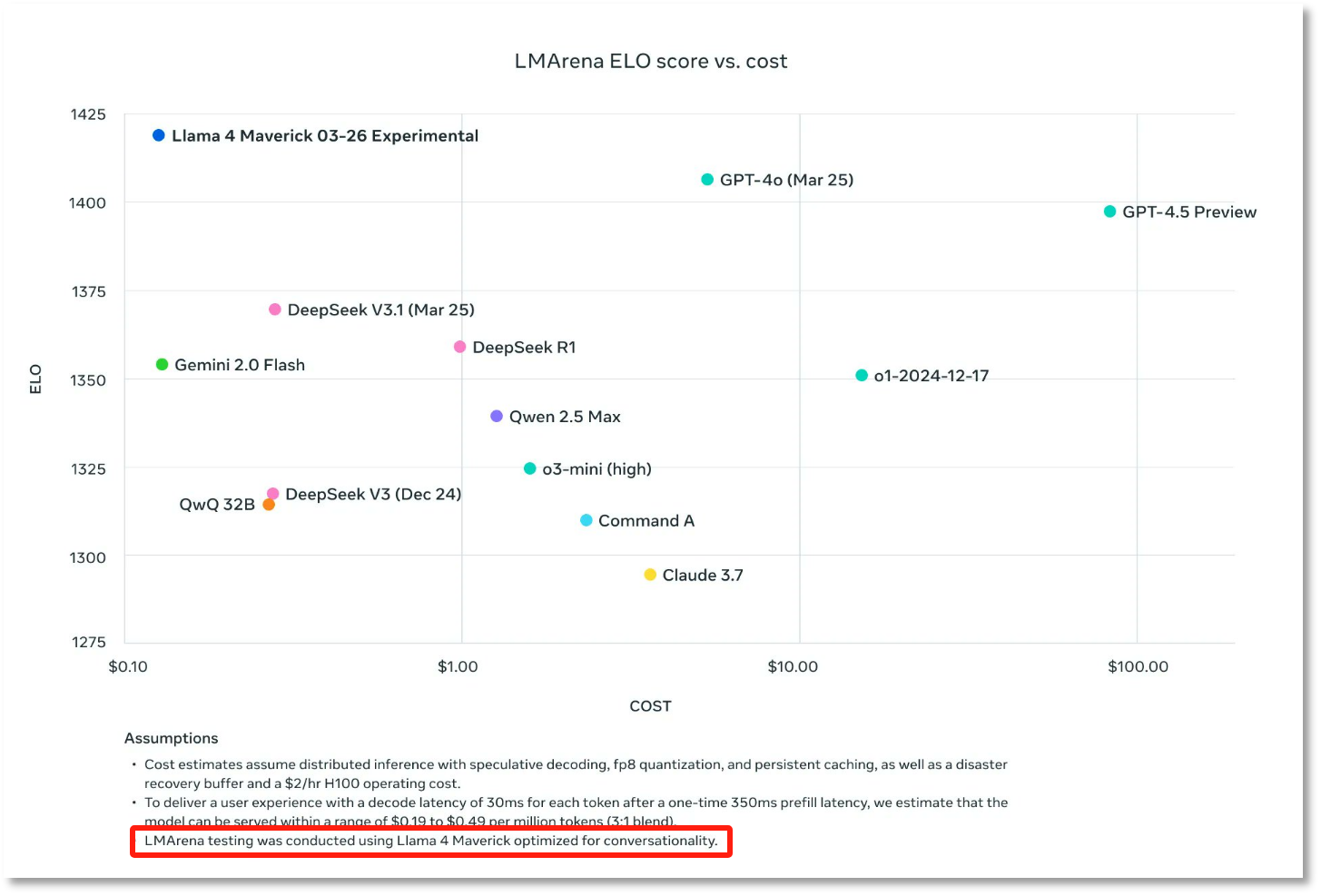
大模型競技場官方也下場“補刀”,指出Meta在大模型競技場使用的并非HuggingFace上供開發者使用的Llama 4版本,而是“針對人類偏好進行優化的定制模型Llama-4-Maverick-03-26-Experimental”。
大模型競技場官方要求Meta對此事作出澄清,并強調其排行榜結果準確可靠,后續將對Llama 4重新進行評測。

圖片來源:X
知名科技媒體TechCrunch也發文,標題直言Meta新AI模型的性能測試“具有一定誤導性”。
文章指出,針對基準測試優化特定版本去打榜,卻給開發者提供“基礎版”的做法,讓開發者難以依據榜單排名準確預估模型在實際應用場景中的真實表現。
《每日經濟新聞》記者發現,在Llama官網提供的性能對比測試圖的最下面,寫著其在大模型競技場上使用的是專門針對對話場景優化的Llama 4 Maverick版本。不過,這一信息的字體極小,很難被注意到。
圖片來源:X
就在Llama 4被集體質疑之時,內部員工的一則爆料帖子,讓Meta陷入了更深的輿論漩渦之中。
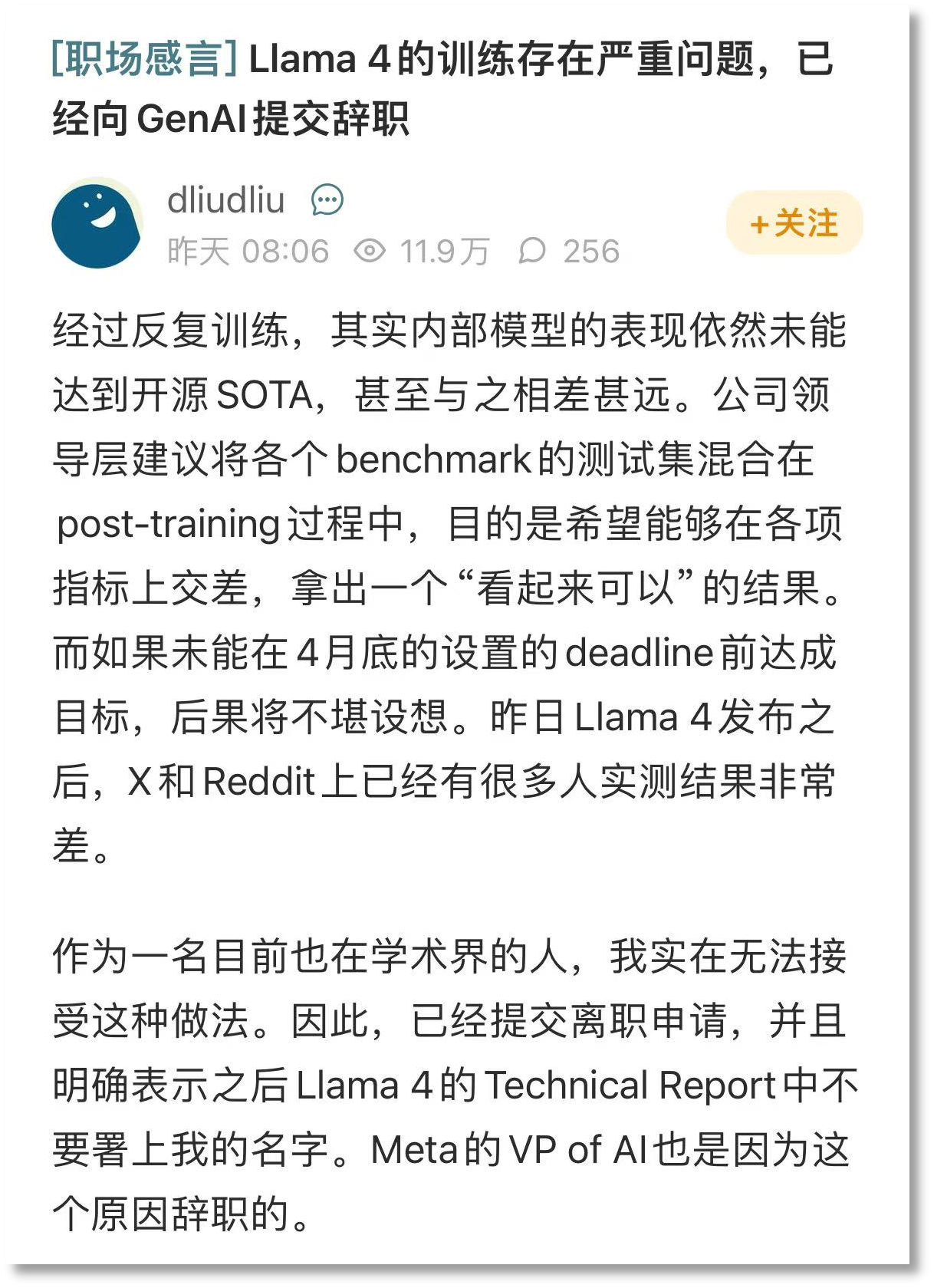
4月7日,在海外留學求職交流論壇“一畝三分地”上,一位自稱參與了Llama 4訓練的內部員工爆料稱,Llama 4模型訓練測試集作弊,并表示自己已因此辭職。
圖片來源:一畝三分地
該員工透露,盡管團隊反復努力訓練,Llama 4的內部模型性能始終無法達到開源SOTA(State-of-the-Art,頂尖水平)基準,且差距明顯。為達成目標,公司領導層提出在訓練后期將各種基準測試的測試集數據混入訓練或微調數據中,以此在各項指標上達成目標,交出一份“好看”的成績單。
這位內部員工表示,自己無法接受公司這種做法,甚至辭職信中明確要求不要在Llama 4技術報告中掛名。
就在Llama 4發布前幾天,Meta AI研究主管喬爾·皮諾(Joelle Pineau)在工作8年之后突然宣布離職。
不過,由于發帖人并未實名,該帖子的真實性暫無法核實。在帖子下方評論區,已有數名Meta員工實名進行辟謠。
Meta研究科學家主管Licheng Yu稱,團隊絕不存在針對測試集過擬合訓練的情況。

圖片來源:一畝三分地
另一位Meta高級AI研究科學家Di Jin也反駁道:“我參與了微調和強化學習的數據混合工作,并沒有這種(將基準測試的測試集數據混入訓練或微調數據)情況。”
并且,Di Jin還指出,近期離職的AI研究主管喬爾?皮諾,實則并非Meta GenAI團隊成員,沒有參與GenAI的任何模型訓練工作。

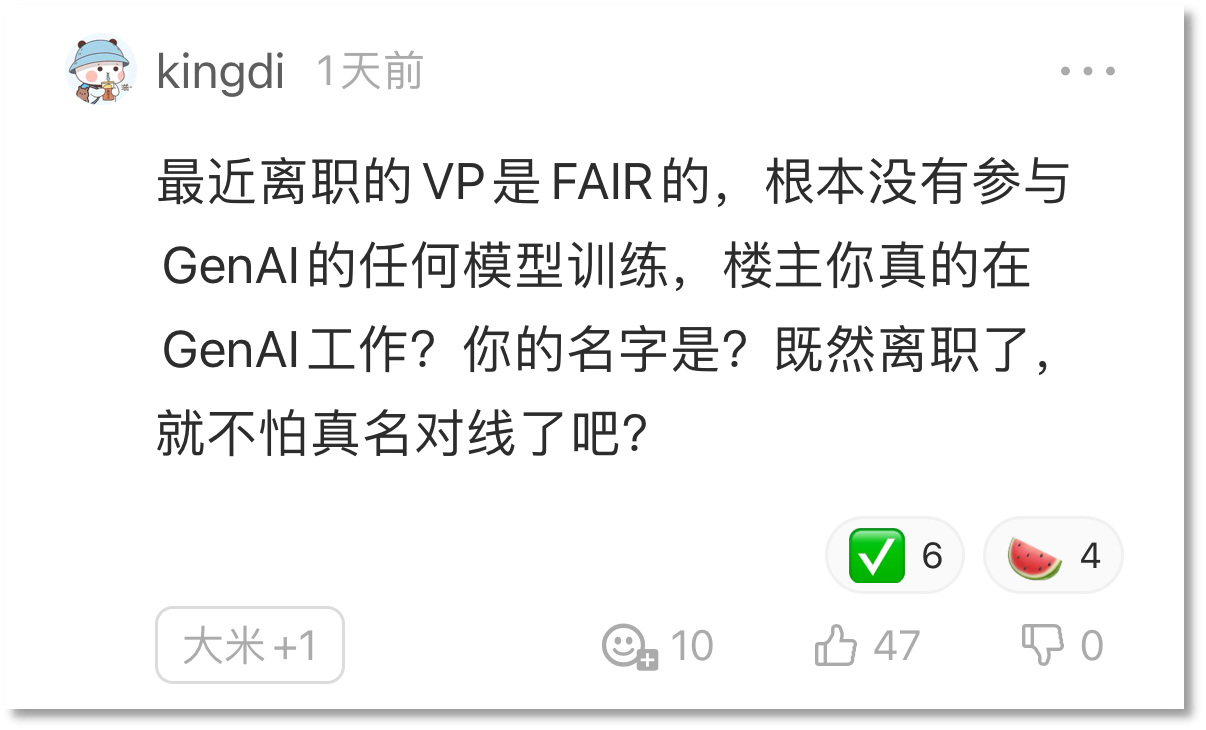
圖片來源:一畝三分地
根據Meta的組織架構體系,喬爾?皮諾是FAIR的副總裁,而FAIR實際上是Meta內部與GenAI完全獨立的組織,GenAI才是負責Llama項目的組織。
針對外界對Llama 4模型的諸多質疑,當地時間4月7日,Meta生成式AI副總裁艾哈邁德·阿爾·達赫勒(Ahmad Al-Dahle)在社交平臺X上公開回應,明確指出相關說法毫無事實依據。
同時,達赫勒指出,部分用戶通過不同云服務商使用Llama 4模型時,遭遇了質量不穩定問題。他對此解釋道:“由于我們在模型準備好后就迅速發布,因此預計需要幾天的時間來調整所有公開版本。后續,Meta將持續進行錯誤修復工作,并與合作伙伴保持溝通。”
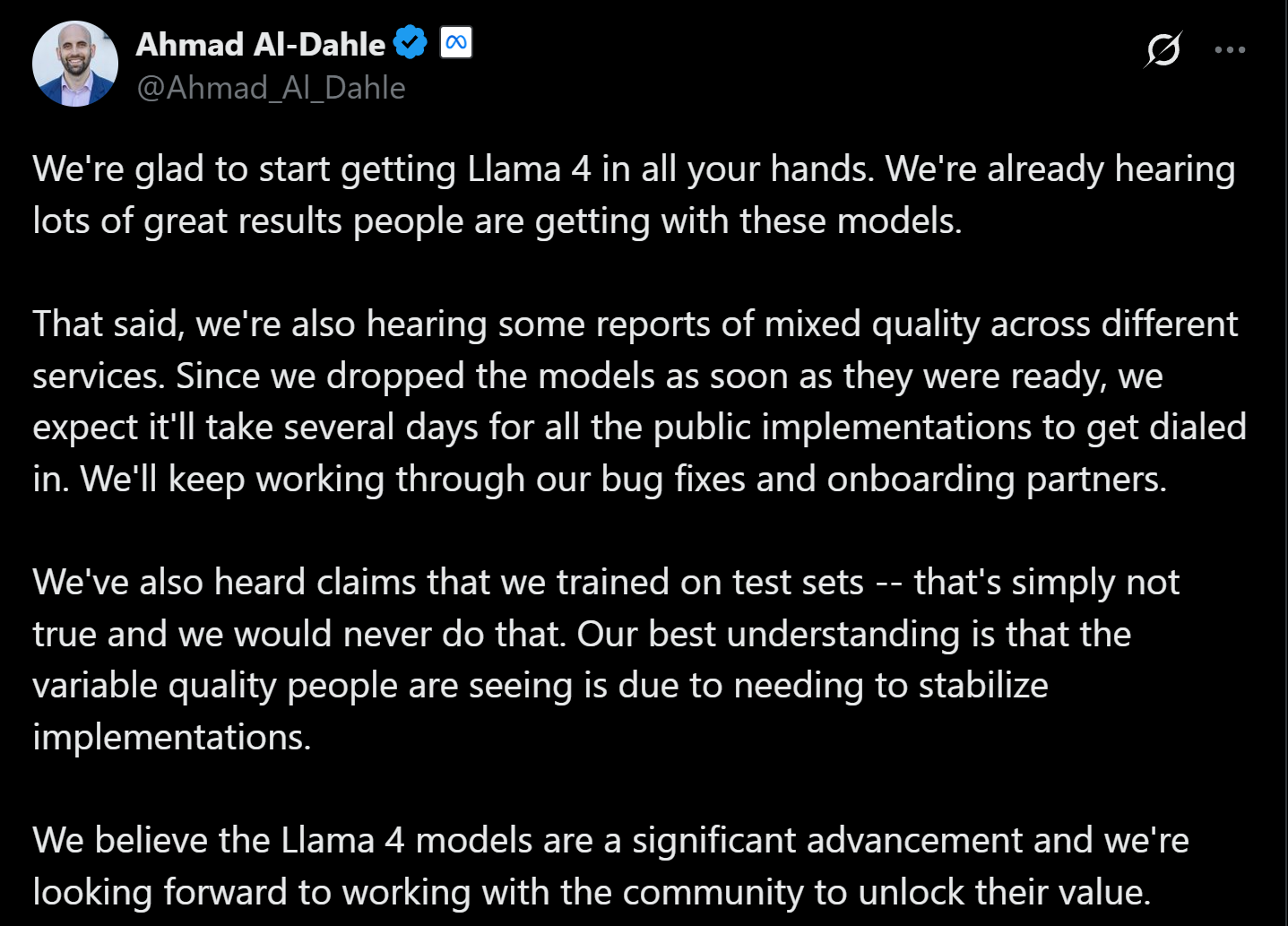
圖片來源:X
此外,Meta首席AI科學家、圖靈獎得主Yann LeCun也轉發了該帖子,為Llama 4聲援“站臺”。
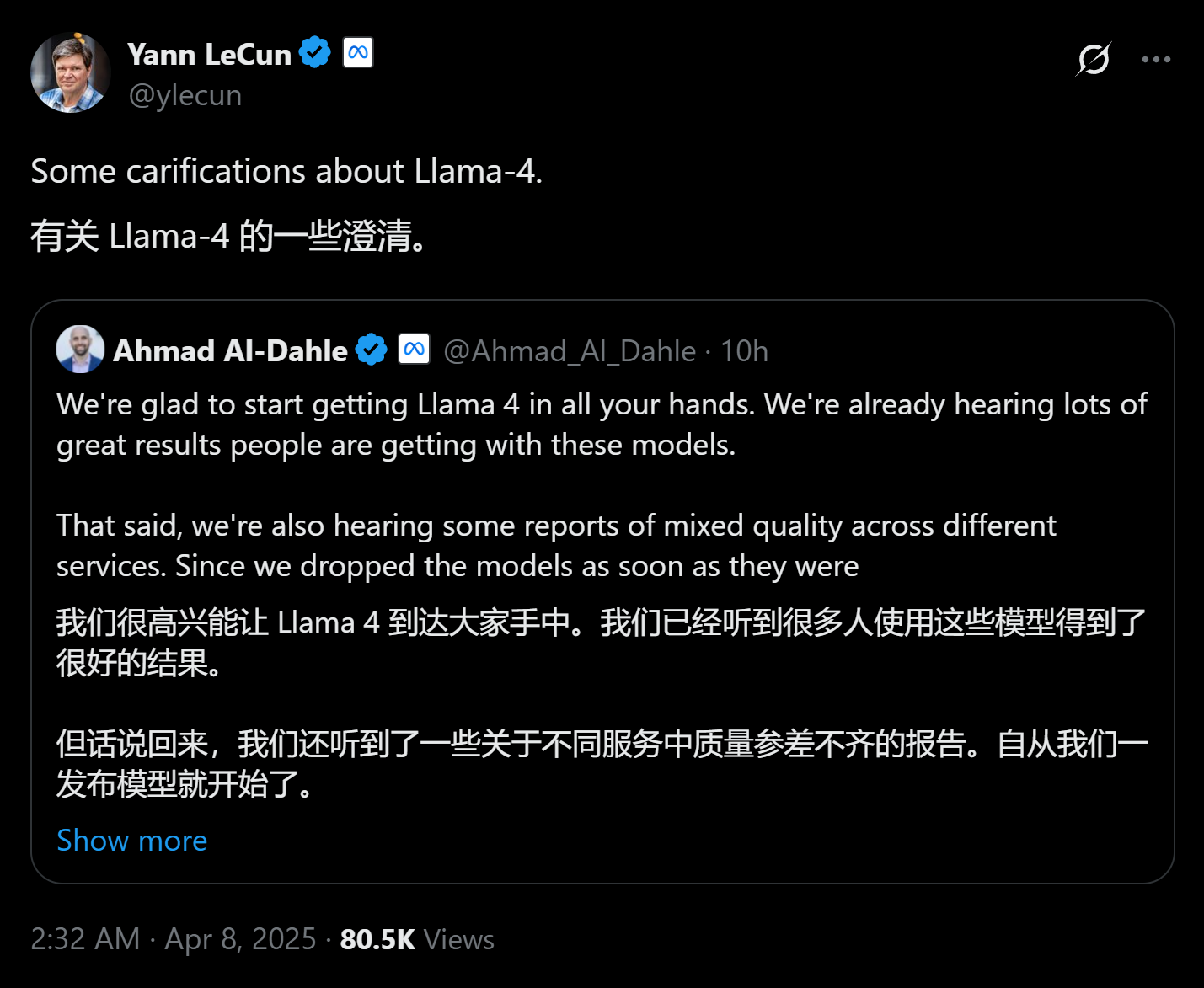
圖片來源:X
如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP














